| Tusk | 90% | Covers 100% of lines in PR, average of 10.0 tests generated | Always follows existing pattern for mocking the Users and Resource services. 10% of the time it suggests test cases opposite to expected behavior. | Generates both passing tests and failing tests that are valid edge cases |
| Cursor (Claude 3.7 Sonnet) | 0% | Moderate coverage, average of 8.0 tests generated | 80% of the time it follows existing pattern for mocking the Users and Resource services. 60% of the time it suggests test cases opposite to expected behavior. | Only generates passing tests, misses edge cases. 20% of the time it finds failing tests in its thinking but excludes them from output during iteration. |
| Cursor (Gemini 2.5 Pro) | 0% | Moderate coverage, average of 8.2 tests generated | 0% of the time it follows existing pattern for mocking the Users and Resource services. 100% of the time it suggests test cases opposite to expected behavior. 40% of the time it created a test file with incorrect naming. | Only generates passing tests, misses edge cases |
| Claude Code | 0% | Fair coverage, average of 6.8 tests generated | 60% of the time it follows existing pattern for mocking the Users and Resource services. 80% of the time it suggests test cases opposite to expected behavior. | Only generates passing tests, misses edge cases |
 ## How We Differ
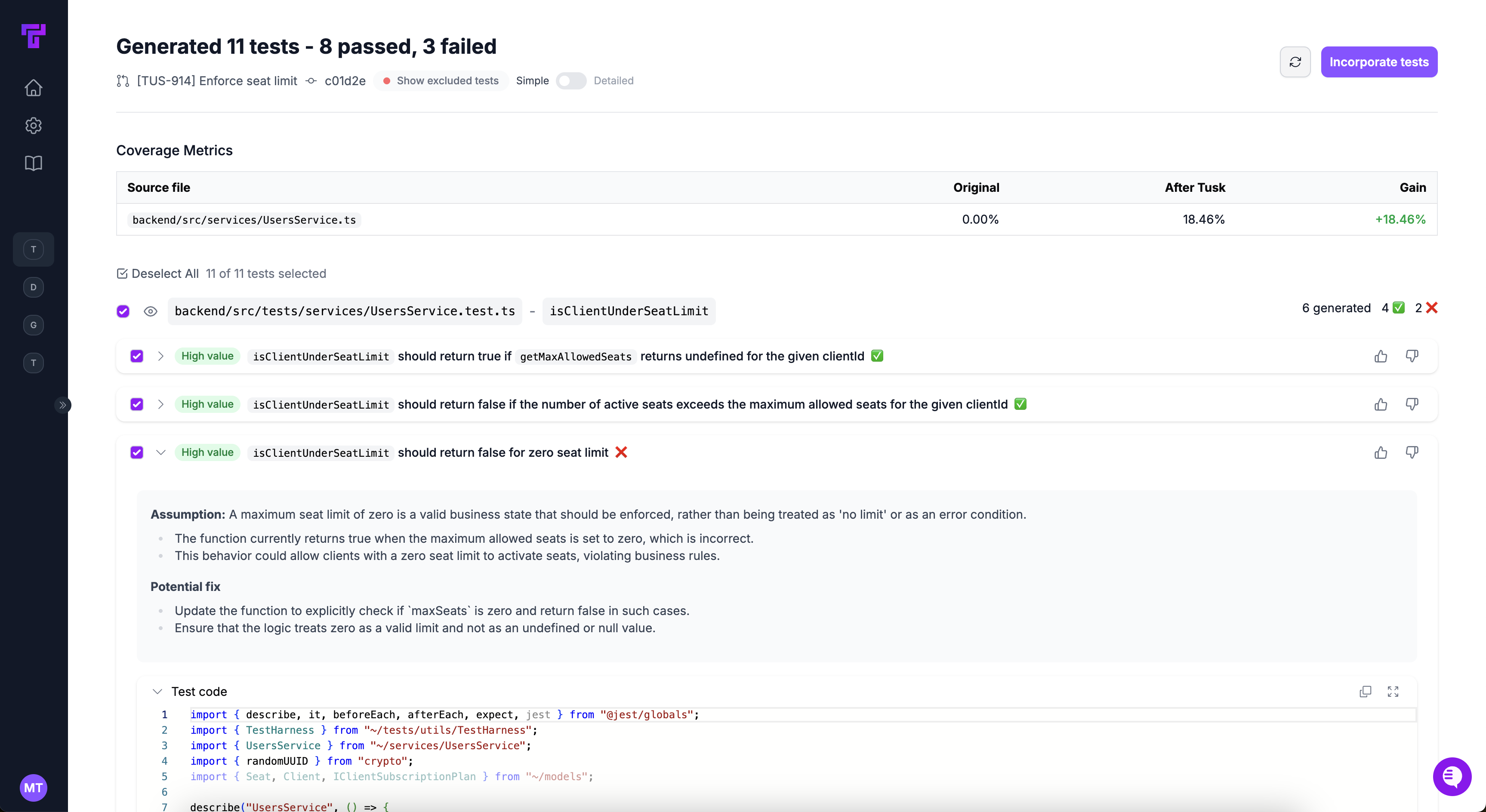
* Tusk **self-runs the tests** it generates and **auto-iterates** on its output so you can be confident that its tests are checking for relevant edge cases. Other test generation and code review tools do not reliably execute tests without a human in the loop.
* Tusk is a PR check, which allows us to **use more compute to reason** if a test should be added or filtered out. AI co-pilots in your IDE are optimized for latency and snippet acceptance, and so tend to generate only passing tests.
* Tusk ingests your **testing guidelines** and documentation so that it can generate tests that are inline with your team's testing best practices.
## Benchmarking
## How We Differ
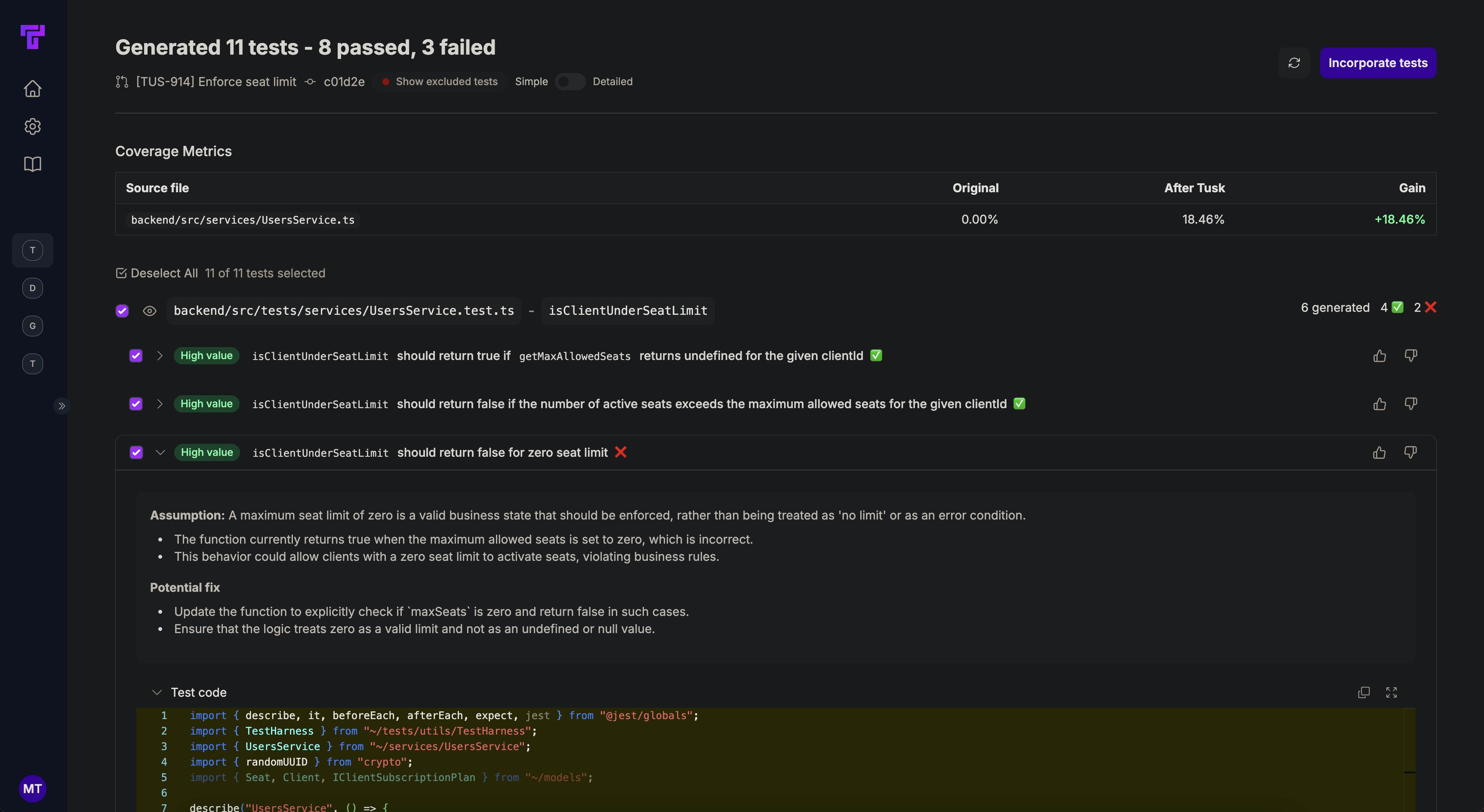
* Tusk **self-runs the tests** it generates and **auto-iterates** on its output so you can be confident that its tests are checking for relevant edge cases. Other test generation and code review tools do not reliably execute tests without a human in the loop.
* Tusk is a PR check, which allows us to **use more compute to reason** if a test should be added or filtered out. AI co-pilots in your IDE are optimized for latency and snippet acceptance, and so tend to generate only passing tests.
* Tusk ingests your **testing guidelines** and documentation so that it can generate tests that are inline with your team's testing best practices.
## Benchmarking