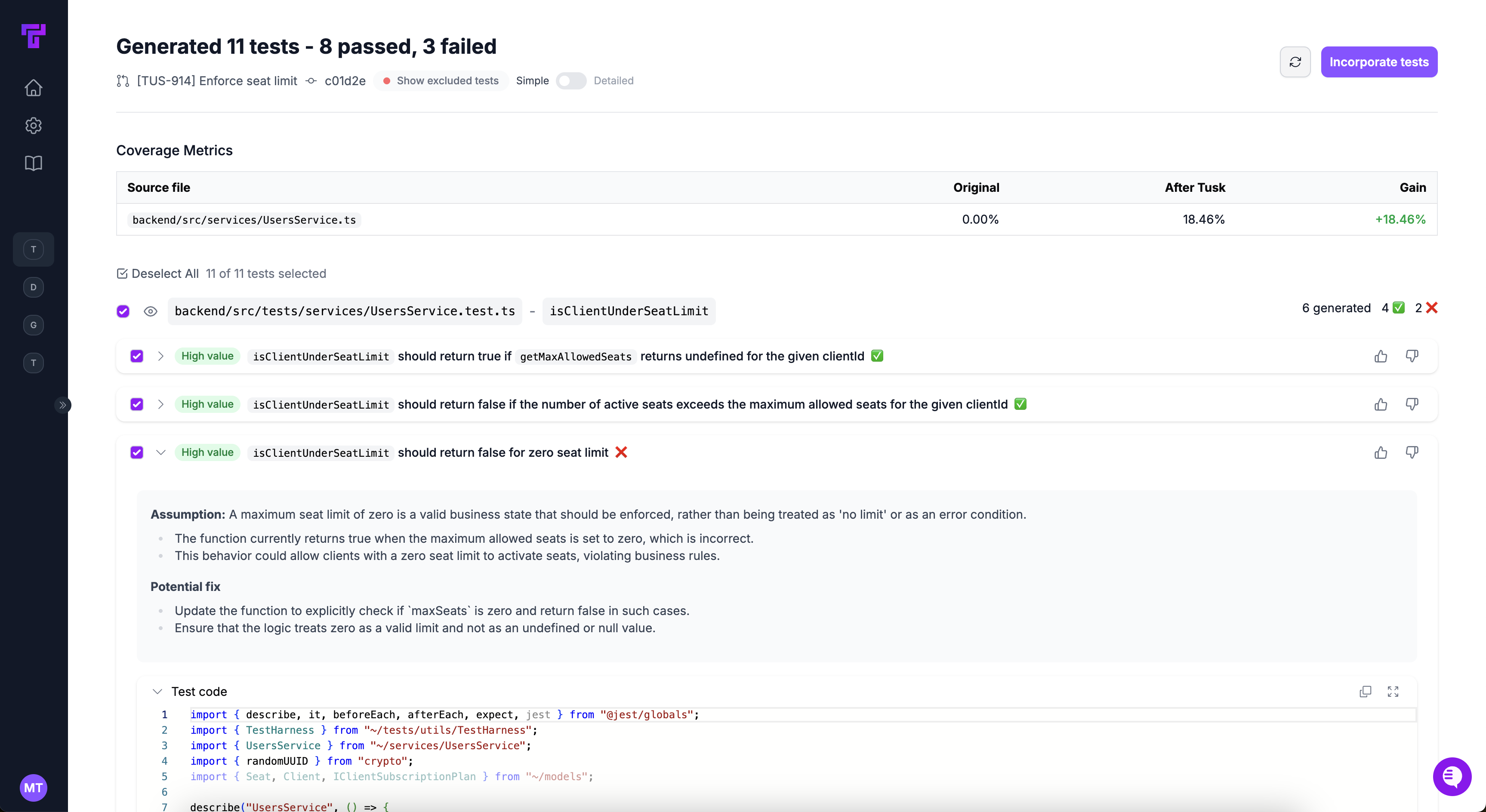
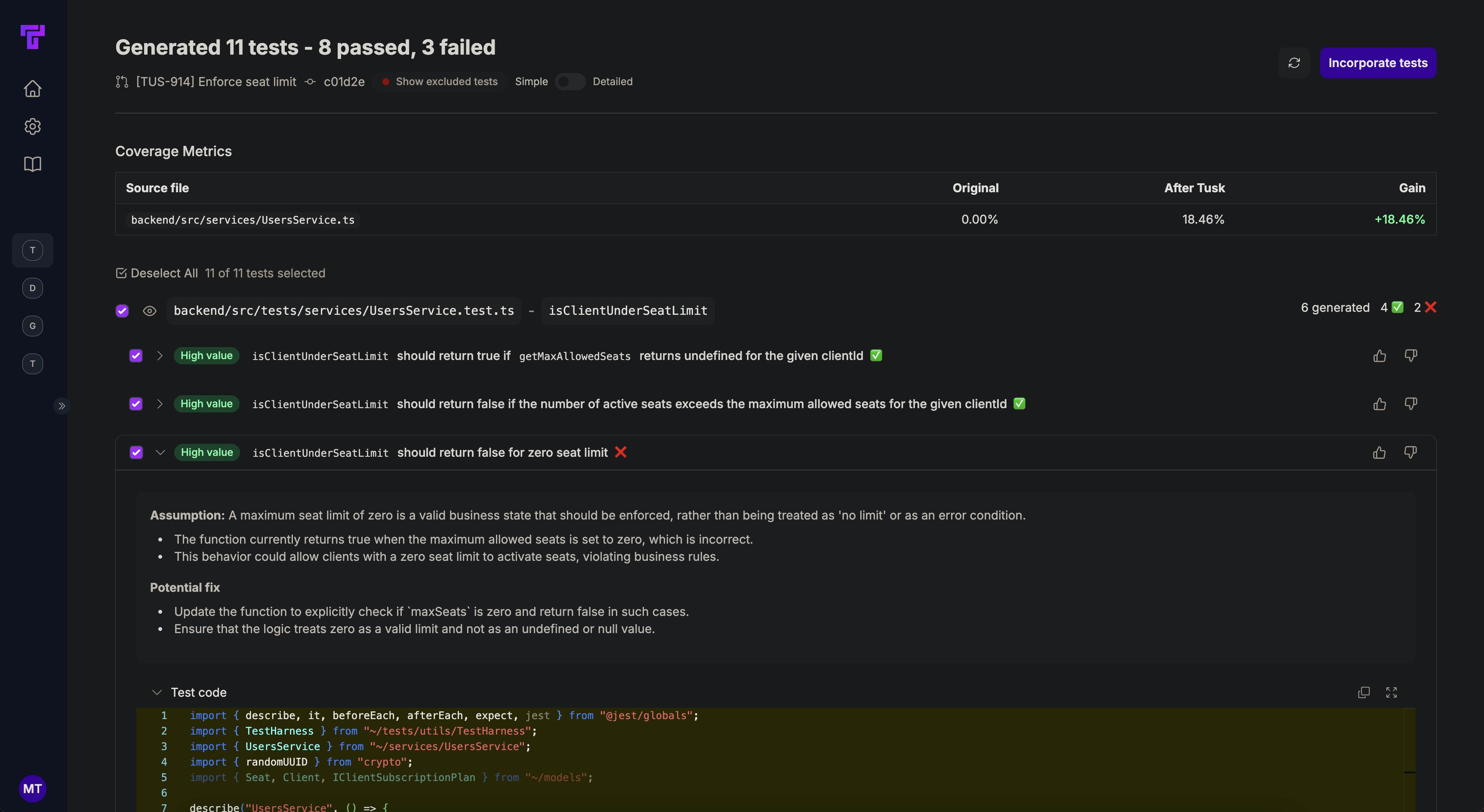
| Tusk | 90% | Covers 100% of lines in PR, average of 10.0 tests generated | Always follows existing pattern for mocking the Users and Resource services. 10% of the time it suggests test cases opposite to expected behavior. | Generates both passing tests and failing tests that are valid edge cases |
| Cursor (Claude 3.7 Sonnet) | 0% | Moderate coverage, average of 8.0 tests generated | 80% of the time it follows existing pattern for mocking the Users and Resource services. 60% of the time it suggests test cases opposite to expected behavior. | Only generates passing tests, misses edge cases. 20% of the time it finds failing tests in its thinking but excludes them from output during iteration. |
| Cursor (Gemini 2.5 Pro) | 0% | Moderate coverage, average of 8.2 tests generated | 0% of the time it follows existing pattern for mocking the Users and Resource services. 100% of the time it suggests test cases opposite to expected behavior. 40% of the time it created a test file with incorrect naming. | Only generates passing tests, misses edge cases |
| Claude Code | 0% | Fair coverage, average of 6.8 tests generated | 60% of the time it follows existing pattern for mocking the Users and Resource services. 80% of the time it suggests test cases opposite to expected behavior. | Only generates passing tests, misses edge cases |